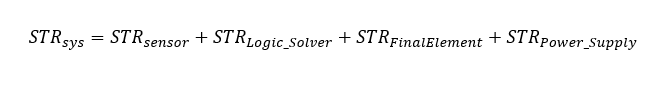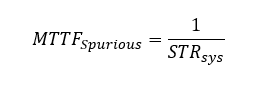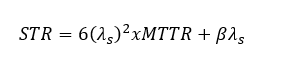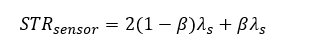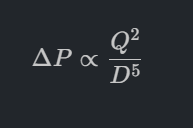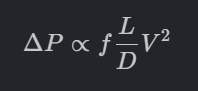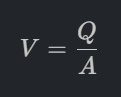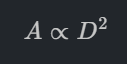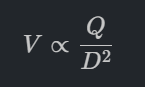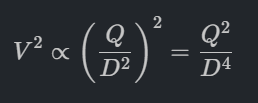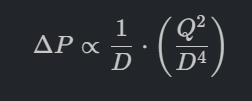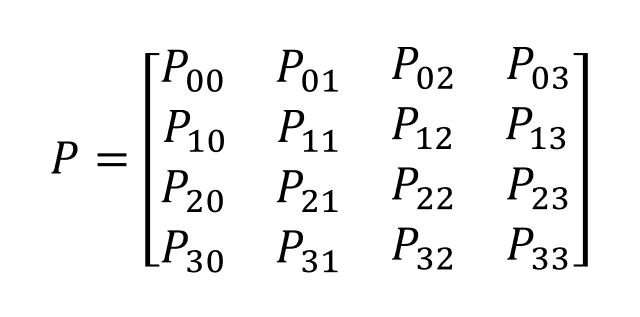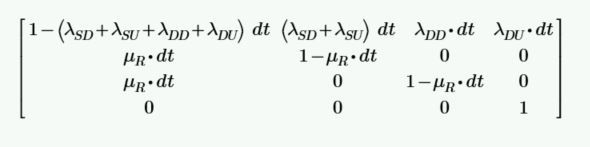ผลกระทบ: หากเลือกขนาดท่อเล็กลงเพียงนิดเดียว ปั๊มที่เลือกจะต้องมี Total Dynamic Head (TDH) หรือแรงดันด้านขาออกที่สูงขึ้นอย่างมหาศาลเพื่อเอาชนะแรงเสียดทานในท่อที่เพิ่มขึ้นนั้น เพื่อให้ได้อัตราการไหลเท่าเดิม
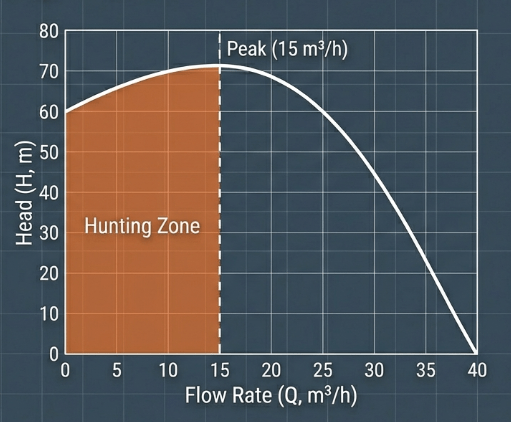
Hunting Zone หรือมักถูกเรียกว่าพื้นที่การทำงานที่ไม่เสถียร – Unstable Operating Region เกี่ยวข้องโดยตรงกับลักษณะกราฟความสัมพันธ์ระหว่าง Head และ Flow (H-Q Curve) ของปั๊มที่ไม่เหมาะสม โดยมีรายละเอียดดังนี้
Hunting เกิดขึ้นได้อย่างไร?
ปกติแล้ว กราฟสมรรถนะของปั๊มที่ดีควรเป็นแบบ “Stable Curve” (เสถียร) คือกราฟที่ค่า Head จะค่อยๆ ลดลงเมื่ออัตราการไหล (Flow) เพิ่มขึ้น หรือกลับกันคือ เพิ่มขึ้นอย่างต่อเนื่องจนถึง Shut-off pressure (Continuously Rising to Shut-off)
Hunting Zone คือช่วงพื้นที่ทางด้านซ้ายของจุดยอดกราฟนี้ (ช่วงที่กราฟกำลังไต่ขึ้น)
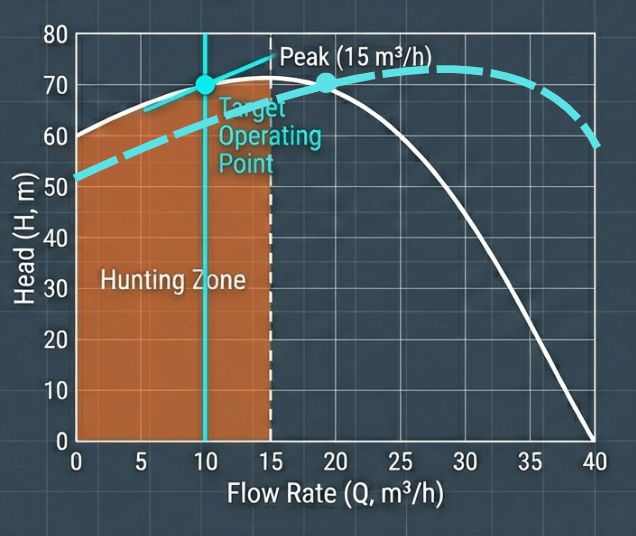
ในช่วง Hunting Zone หากลากเส้น System Curve (ความต้องการของระบบ) ตัดผ่านกราฟปั๊ม อาจจะเกิดจุดตัดได้ถึง 2 จุด (คือจุดที่ Flow ต่ำและ Flow สูงที่ให้ Head เท่ากัน)
Hunting อันตรายอย่างไร
การแกว่งตัว (Surging/Oscillation): เมื่อปั๊มทำงานในโซนนี้ ปั๊มจะไม่สามารถรักษาจุดทำงานให้นิ่งได้ หาก Head ของระบบสูงกว่า Head ที่ปั๊มทำได้ในช่วงนั้น Flow จะหยุดไหลชั่วขณะ (Flow drops to zero) ทำให้เช็ควาล์วปิด เมื่อวาล์วปิด Head ในท่อจะตกลง ปั๊มก็จะดันน้ำออกมาใหม่ วนเวียนไปมา
อาการ: ระบบจะเกิดการกระชากไปมา (Surge back and forth) ระหว่างจุดที่ไม่มีการไหล (No flow) กับจุดที่มีแรงดันสูงสุด สลับกันไปเรื่อยๆ คล้ายเครื่องยนต์ที่รอบเดินเบาไม่นิ่ง (Hunts for speed)
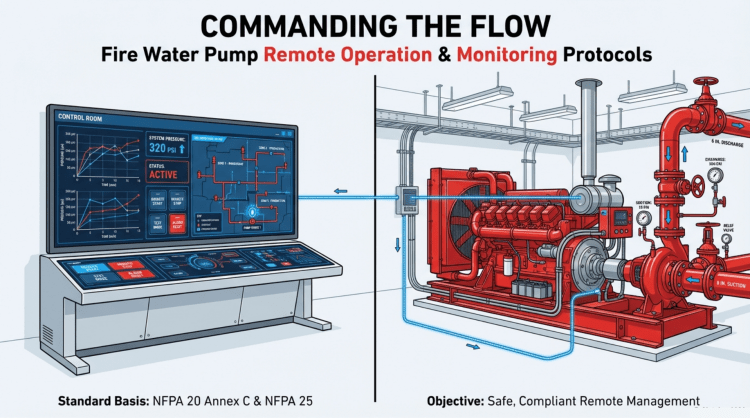
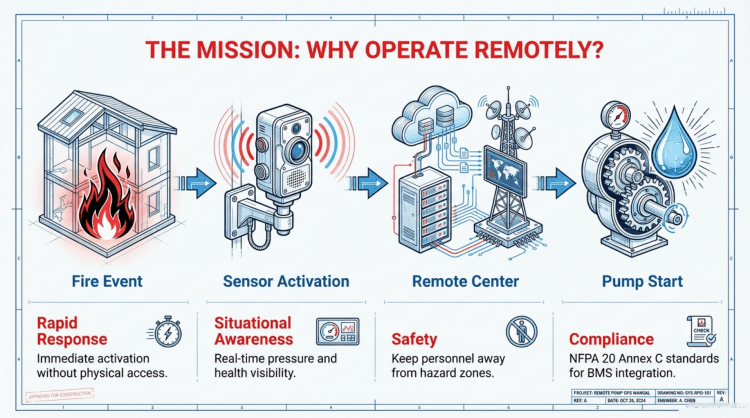
จากข้อมูลในเอกสาร NFPA 20 (Standard for the Installation of Stationary Pumps for Fire Protection) ฉบับปี 2019 มีข้อกำหนดที่ ห้ามไม่ให้มีฟังก์ชัน Remote Stop (การสั่งหยุดเครื่องสูบน้ำจากระยะไกล) ในกรณีทั่วไป เพื่อป้องกันการหยุดทำงานของปั๊มน้ำดับเพลิงโดยไม่ได้ตั้งใจหรือโดยพลการในขณะเกิดเหตุเพลิงไหม้ แต่มีข้อยกเว้นบางประการ ดังนี้
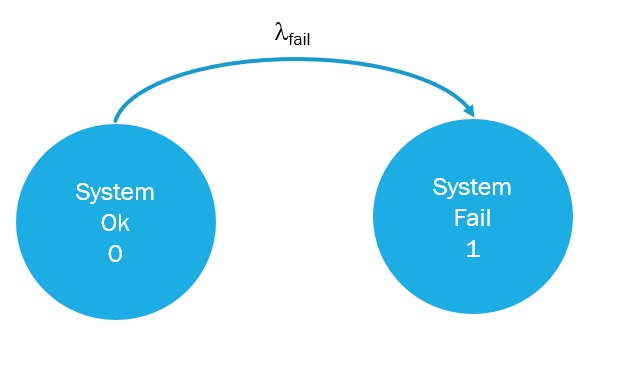
บทความนี้จะนำเสนอและอธิบายถึง Markov Model ซึ่งเป็นเทคนิคการสร้างแบบจำลองทางคณิตศาสตร์ที่ให้ค่าที่แม่นยำสูง เพื่อใช้ในการคำนวณค่าความน่าจะเป็นของการล้มเหลวเมื่อมีความต้องการ (Probability of Failure on Demand หรือ PFD) และสนับสนุนกระบวนการทวนสอบระดับความสมบูรณ์ด้านความปลอดภัย (SIL Verification) ได้อย่างน่าเชื่อถือ
Probability of Failure on Demand (PFD) คืออะไร
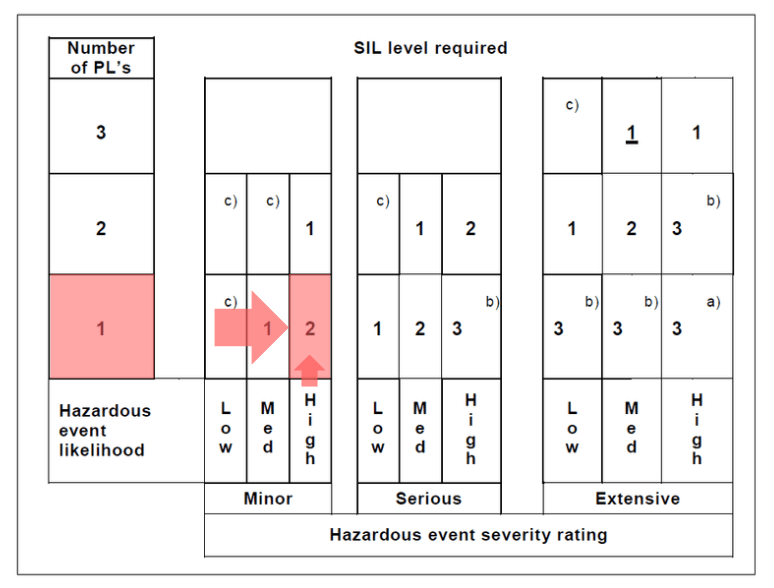
ก่อนที่จะเจาะลึกถึง Markov Model สิ่งสำคัญคือต้องทำความเข้าใจหน่วยวัดพื้นฐานที่ใช้ประเมินประสิทธิภาพของระบบความปลอดภัย นั่นคือ ความน่าจะเป็นของการล้มเหลวเมื่อมีความต้องการ (Probability of Failure on Demand หรือ PFD) ซึ่งถือเป็นรากฐานที่สำคัญที่สุดของการจำแนกระดับความสมบูรณ์ด้านความปลอดภัย หรือ SIL (Safety Integrity Level)
โดย Probability of Failure on Demand (PFD) คือค่าความน่าจะเป็นที่ฟังก์ชันด้านความปลอดภัย (Safety Instrumented Function – SIF) จะล้มเหลวและไม่สามารถทำงานตามที่ออกแบบไว้ได้เมื่อเกิดสภาวะที่ต้องการการทำงานของระบบ (Demand) โดยค่า PFD นี้จะบ่งชี้ถึงประสิทธิภาพที่จำเป็นของ SIF เพื่อให้บรรลุค่า Risk Reduction Factor (RRF) หรือปัจจัยการลดความเสี่ยงที่ต้องการ ทำให้ PFD ไม่ใช่เป็นเพียงค่าความน่าจะเป็นเชิงนามธรรม แต่เป็นเป้าหมายด้านประสิทธิภาพที่จับต้องได้และผูกโยงกับการลดความเสี่ยงโดยตรง
สำหรับวัตถุประสงค์ของการทวนสอบค่า SIL (SIL Verification) ค่าที่นำมาใช้โดยเฉพาะคือ ค่าเฉลี่ยความน่าจะเป็นของการล้มเหลวเมื่อมีความต้องการ (Average Probability of Failure on Demand หรือ PFDavg) ซึ่งแสดงถึงค่าเฉลี่ยความไม่พร้อมใช้งาน (Unavailability) ของฟังก์ชันความปลอดภัยตลอดช่วงระยะเวลาการทดสอบ (Proof-Test Interval)
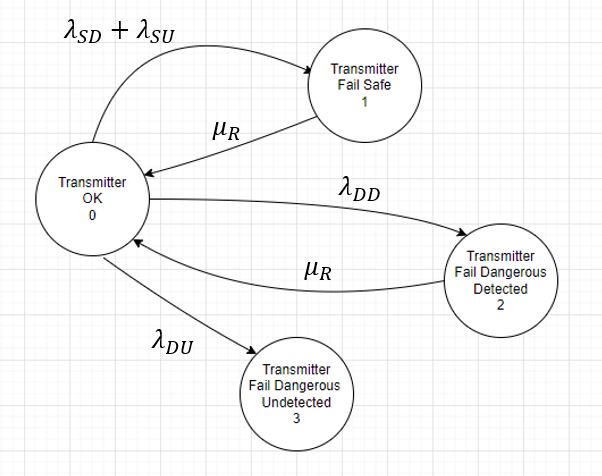
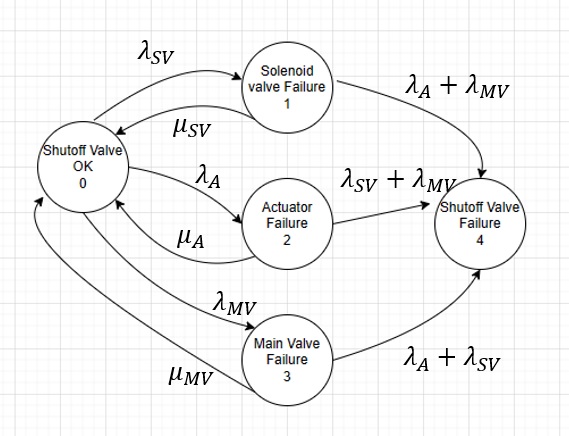
ทำความรู้จัก Markov Model
Markov Model คือแบบจำลองทางคณิตศาสตร์ที่อิงตามสถานะ (State-Based) ซึ่งใช้วิเคราะห์การเปลี่ยนแปลงของระบบระหว่างสถานะการทำงานต่างๆ เมื่อเวลาผ่านไป โดยมีลักษณะเด่นที่สำคัญดังนี้
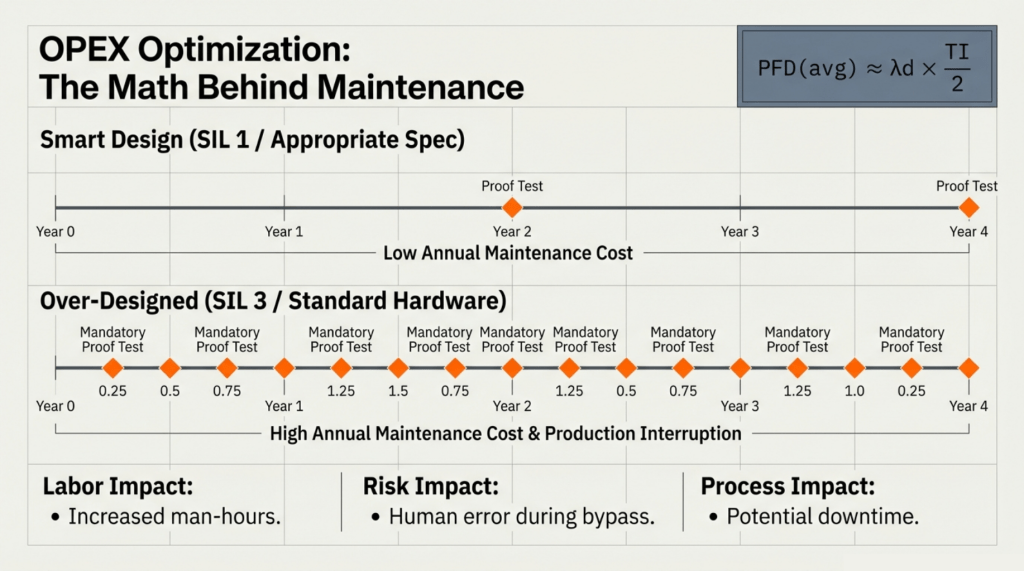
แนวคิดที่ถูกต้องคือการประเมินด้วย “ต้นทุนตลอดอายุการใช้งาน” (Lifecycle Costing – LCC) ซึ่งเป็นวิธีการที่ครอบคลุมค่าใช้จ่ายทั้งหมดของระบบ ตั้งแต่ขั้นตอนการออกแบบ, การจัดซื้อ, การติดตั้ง, ไปจนถึงค่าดำเนินการและบำรุงรักษา (Operating and Maintenance Costs) ที่จะเกิดขึ้นตลอดหลายสิบปีข้างหน้า แนวคิดนี้สอดคล้องกับหลักการที่ว่า “คุณภาพที่ดีมักมาพร้อมกับราคาที่สูงแค่ในขั้นตอนแรก แต่จะช่วยประหยัดได้มากกว่าในระยะยาว” (Quality is free for those who are willing to pay a little more up front) การเลือกของราคาถูกในวันนี้ อาจหมายถึงการต้องจ่ายแพงกว่าอย่างมหาศาลในวันหน้า
Safety Instrumented System (SIS) VS Basic Process Control System (BPCS)
ความแตกต่างระหว่าง BPCS กับ SIS
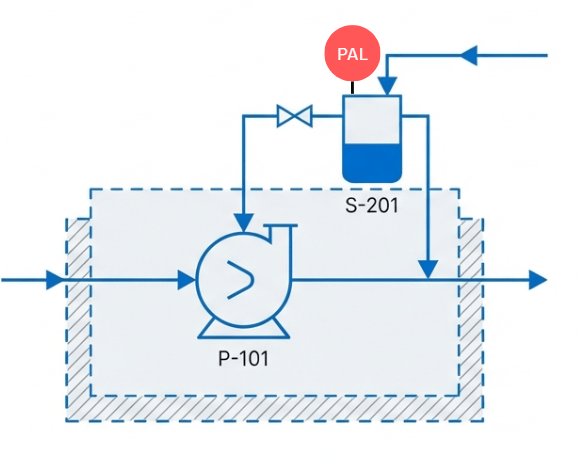
Safety Instrumented System (SIS) และ Basic Process Control System (BPCS) เป็นระบบควบคุมที่มีบทบาทสำคัญในโรงงานอุตสาหกรรมกระบวนการ แต่มี วัตถุประสงค์หลัก และ ลักษณะการทำงาน ที่แตกต่างกันอย่างชัดเจน
โดยที่ SIS คือ Safety Instrumented System (ระบบวัดคุมความปลอดภัย) หรือบางครั้งในโรงงาน อาจจะใช้ชื่อว่า Emergency Shutdown System (ESD) หรือ Instrumented Protection System (IPS) ส่วน BPCS คือ Basic Process Control System (ระบบควบคุมกระบวนการพื้นฐาน) หรือบางครั้งเรียกว่า DCS (Distributed Control System)